

Ever felt tired of reading long articles with lot of repetitive information? reading through bunch of self explanatory paragraphs and miss what matters the most? This article covers the most important points without self descriptive lengthy explanatory part, depicted with illustrations.
Data Partitioning/ Sharding
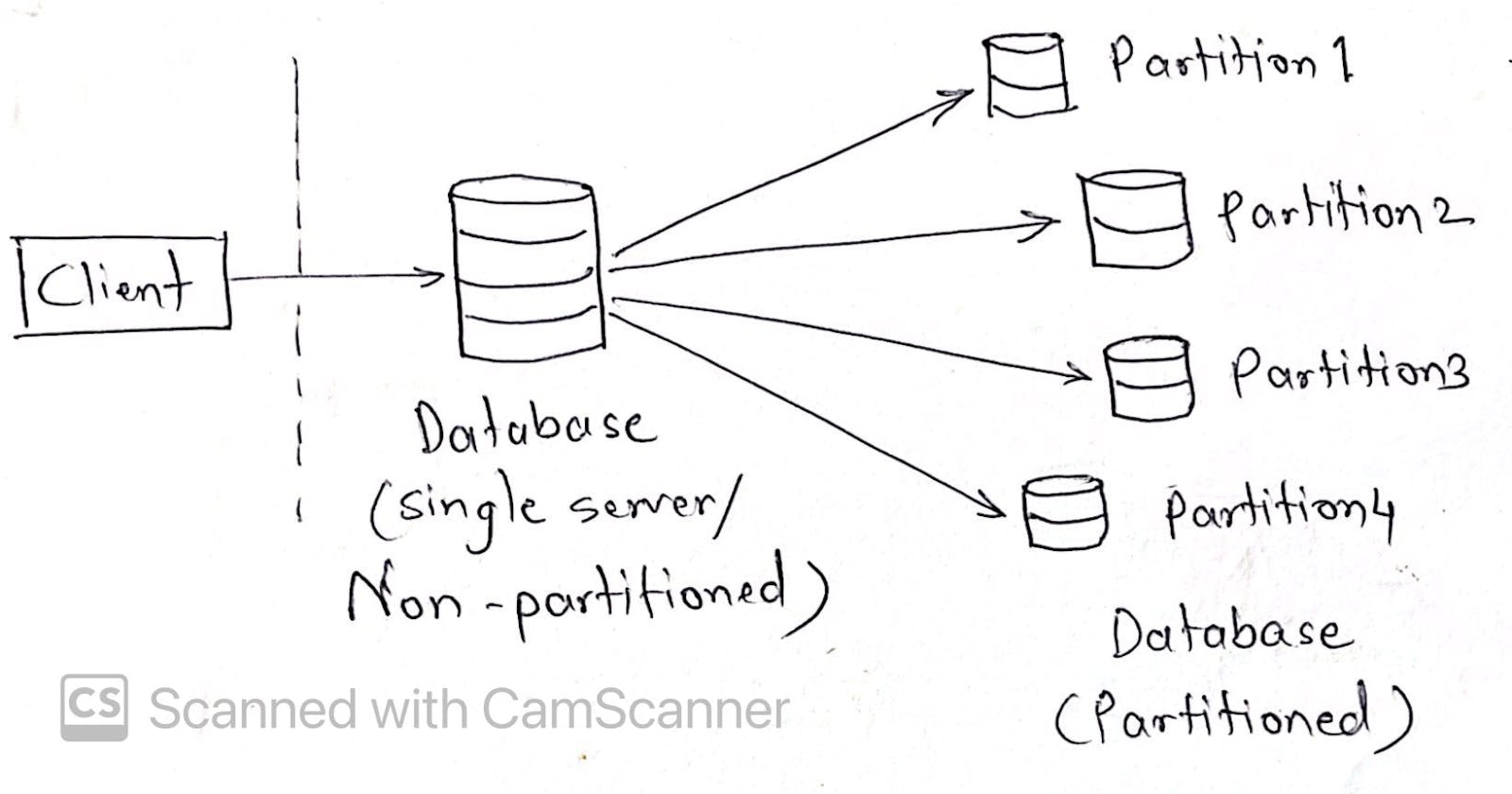
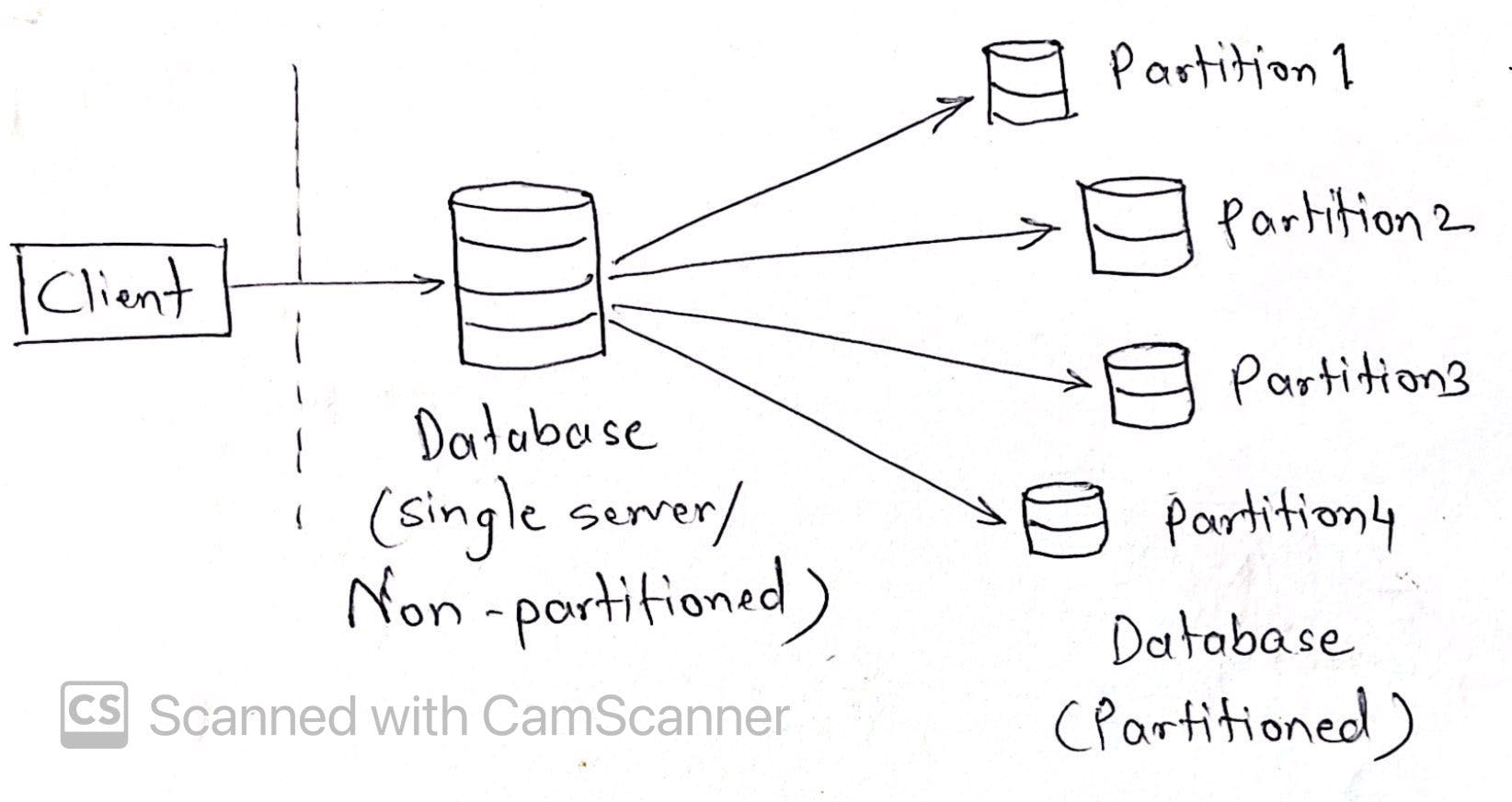
What is data partitioning?
It is process of dividing a large dataset into several smaller partitions placed on different machines. Partitions may reside on same machine (coresident) or different machines
Why to partition? What are the benefits?
Some of the reasons to consider data partition are
- with growth in data and users, single database server can have degraded performance
- we might run out of disc space on a single server
- network bandwidth reaches saturation for a single server to handle
Textually speaking,
- Improve availability: if one partition is unavailable, other partitions are available to query data, eliminating single point of failure
- Improve scalability: adding new machines to scale horizontally makes it easier to increase capacity
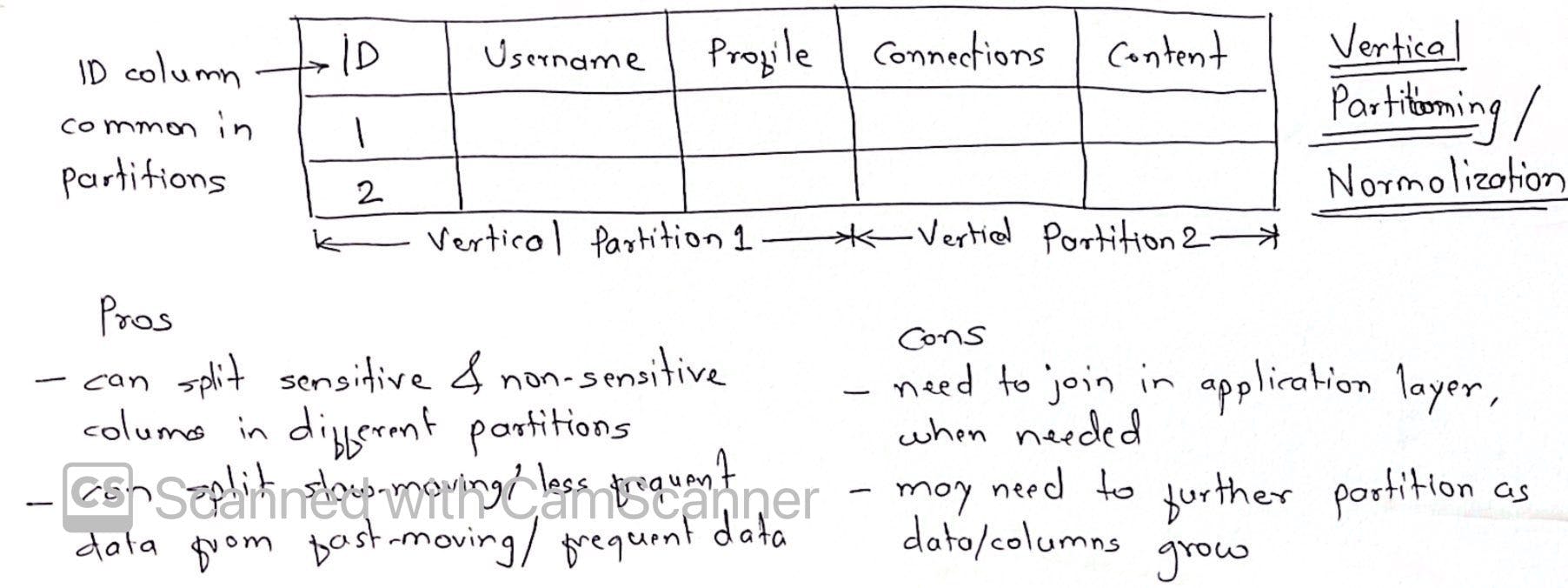
- Improve security: by partitioning sensitive and non-sensitive data on different machines and managing differently/independently
- Increase performance: queries do not need to execute against whole database but instead are focused towards smaller partitions, improving service performance
- Improve data manageability: individual partitions can be managed separately during maintenance
When to partition?
You can think of partitioning, to list a few,
- when tables are too large to fit in memory of a single server
- when new data is added/updated everyday, example, historical vs current data based on months
- when you want to scale up performance of read queries, you can distribute data on machines and achieve better latency and throughput
Data Partitioning Methods
- Horizontal Partitioning
- Vertical Partitioning/ Normalization
- Functional Partitioning: data is partitioned based on functional/contextual dependency (inventory data vs invoice data), can further leverage horizontal/vertical partitioning based on structure of data

Data Partitioning Criteria
- Range based partitioning
covered in schematic of horizontal partitioning above
- Hash based partitioning
Disadvantage of dynamically changing no of partitions can be addressed using Consistent Hashing

- List based partitioning
partition key is selected as list of values instead of range of values

- Composite partitioning
partition the data based on 2 or more partition techniques, example, first range partition based on date and then hash subpartition based on userId. To list few combinations
- Composite range-range
- Composite range-hash
- Composite hash-list