



What is a rate limiter
Rate limiting is preventing frequency of an operation from exceeding a defined limit.
It is commonly used to protect underlying services and resources from unintended and malicious overuse.
Why to rate limit
- Preventing resource starvation: for example, Denial of Service (DoS) attack. One user can bombard the resource starving others
- Security: rate limiting prevents brute force attack on security sensitive functionalities like user login
- Preventing operational costs: auto-scaling resources will unnecessarily scale up in absence of missing rate limiting increasing billing costs to scale up infrastructure
Rate limiting strategies
We can apply rate limiting using number of factors like
- User: limit no of requests from a user in a given timeframe
- Concurrency: limit no of parallel session from a user in a given timeframe
- Demographics: limit no of requests from out of region users to increase availability in target regions
- Server: limit requests to servers like DB connections
Rate limit algorithms
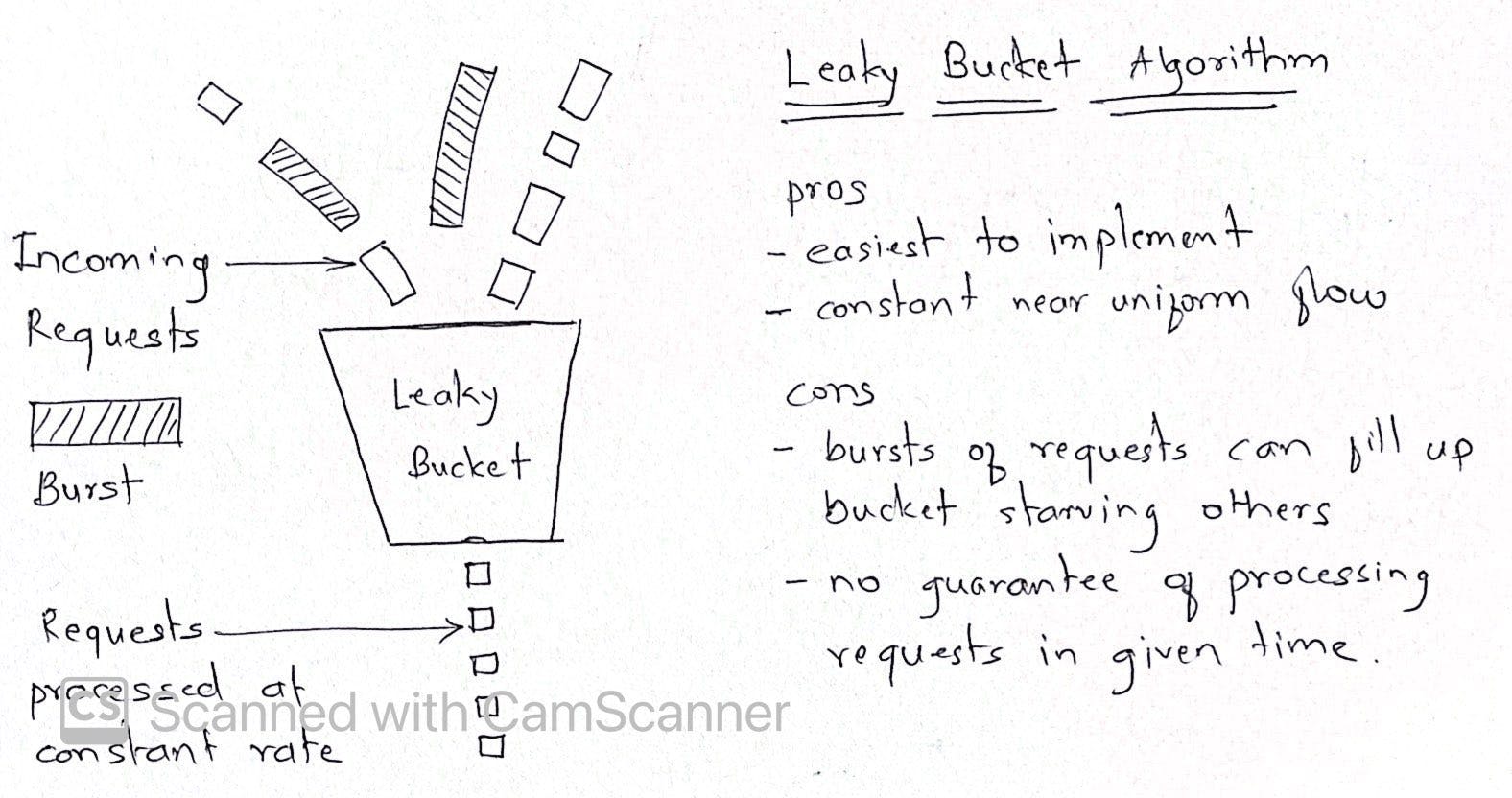
Leaky bucket
Token bucket
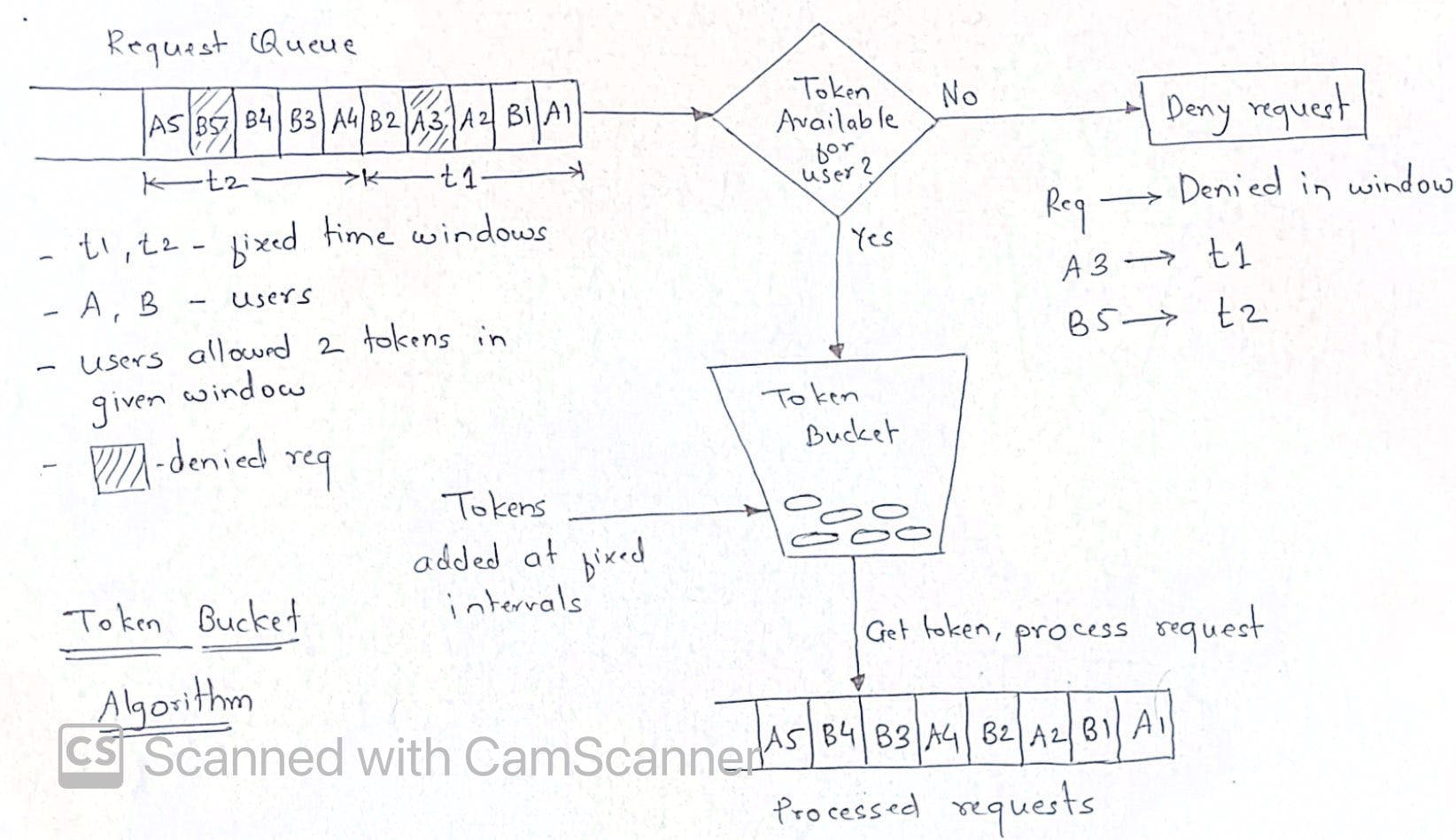
The problem here is it can cause race condition in distributed environment when 2 requests try to fetch token for same user on different application servers
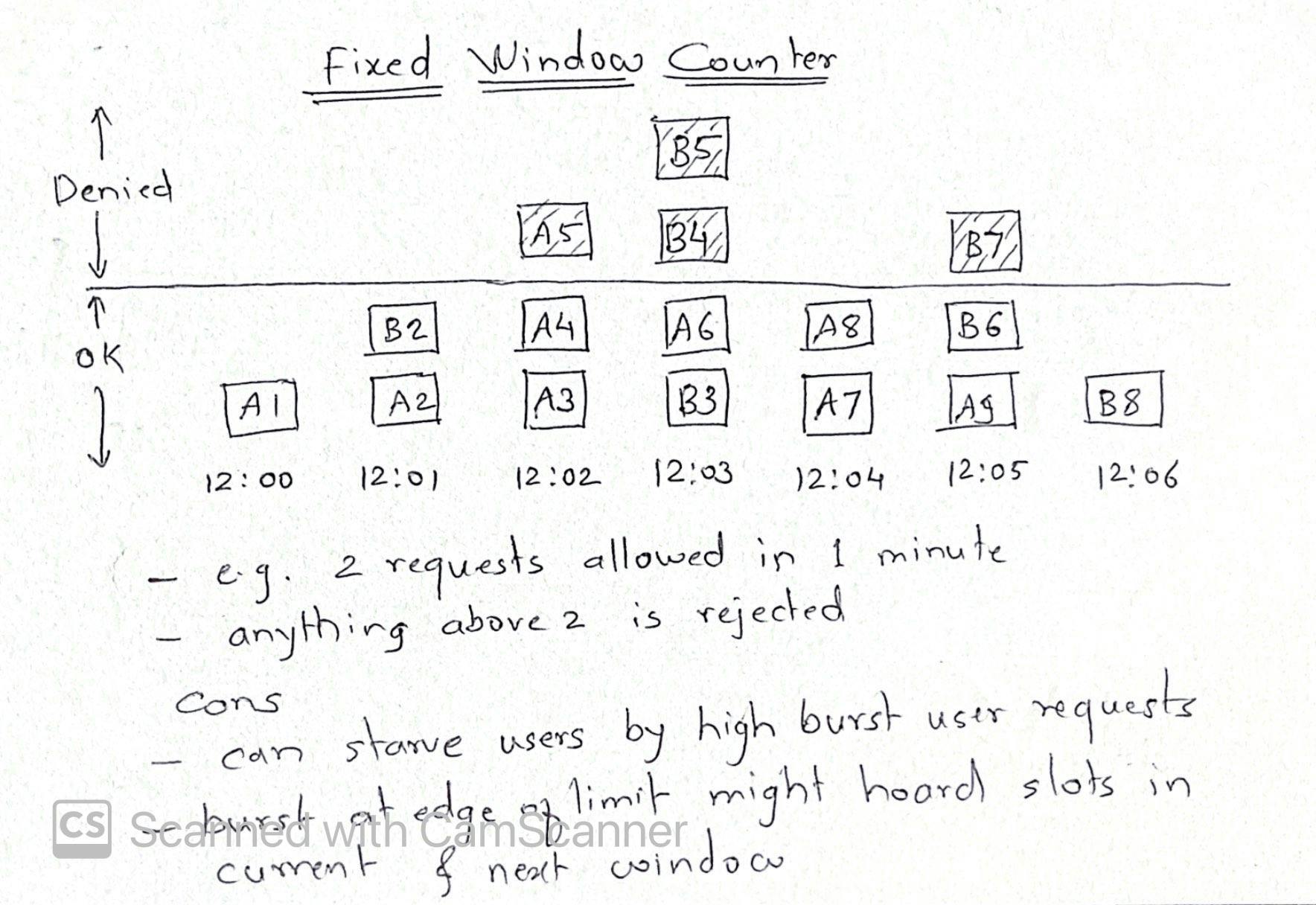
Fixed window counter
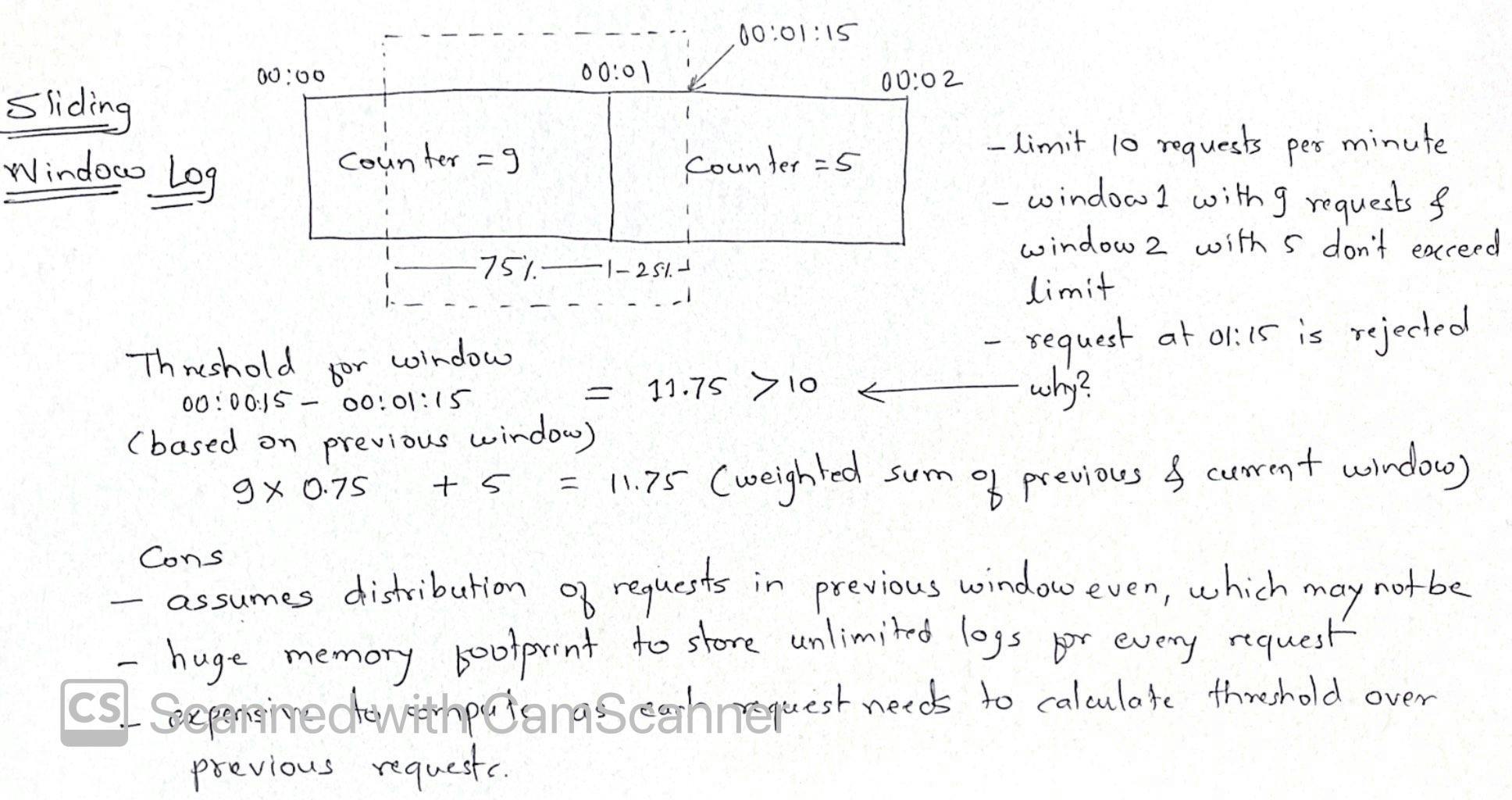
Sliding log
Sliding window
- This is best of both sliding log above and fixed window counter approach.
- For example, we have limit of 10 requests in 1 minute duration. Whenever a request is received (lets say at time t), it will look at count of requests during t and t-1 minute. If the count is greater than limit, it will be rejected else processed.
- This combines low processing cost of fixed window and improving boundary condition of sliding log
Challenges in distributed systems
These algorithms work very well for single servers. In case of complex systems with multiple app servers distributed across different regions and having their own rate limiters, we need to define a global rate limiter. A consumer could surpass the global rate limiter individually if it receives a lot of requests in a small time frame. The greater the number of nodes, the more likely the user will exceed the global limit.
- Inconsistency: a user might not cross rate limit for a single server in a region but it can exceed global limit. To address this, we can use
- Sticky sessions: routing request from a user to a dedicated target server, this has its own downsides like reduced fault tolerance
- Centralized data stores: like Redis but this introduces latency but still is a improved way of handling the inconsistency
- Race condition: when multiple requests are reading count of requests made, specially when count is get-then-set operation and not an atomic operation. We can use synchronization methods or atomic methods to address this but there might be performance penalty