

If you ever answer yes to any of the below, you might have ended on right article. Tired of TL;DR feeling going through huge articles with ton of information? Ever miss out important information due to verbose explanations? Want to focus on what matters and skip self elaborative info? Ugh, so much to read, can someone show me an illustration instead?
What is data replication?
Copying the same data over multiple nodes in distributed systems
Why do we need it?
It is critical to keep the database up and keep on serving queries even during faults like servers or datacenter going down.
Textually speaking,
- Higher Availability: To ensure system keeps on working even if one or fewer nodes fail
- Reduced Latency: To reduce the latency of data queries (By keeping data geographically closer to a user. For example, CDN keeps a copy of replicated data closer to the user. Ever thought how Netflix streams videos with such short latencies!)
- Read Scalability: Read queries can be served from replicated copies of the same data which increases overall throughput of queries
- Network Interruption: System works even under network faults
So how does this work?
Data lies on number of nodes working together to do the job. There are 3 ways to achieve this
- Single leader replication
- Multileader replication
- Leaderless replication
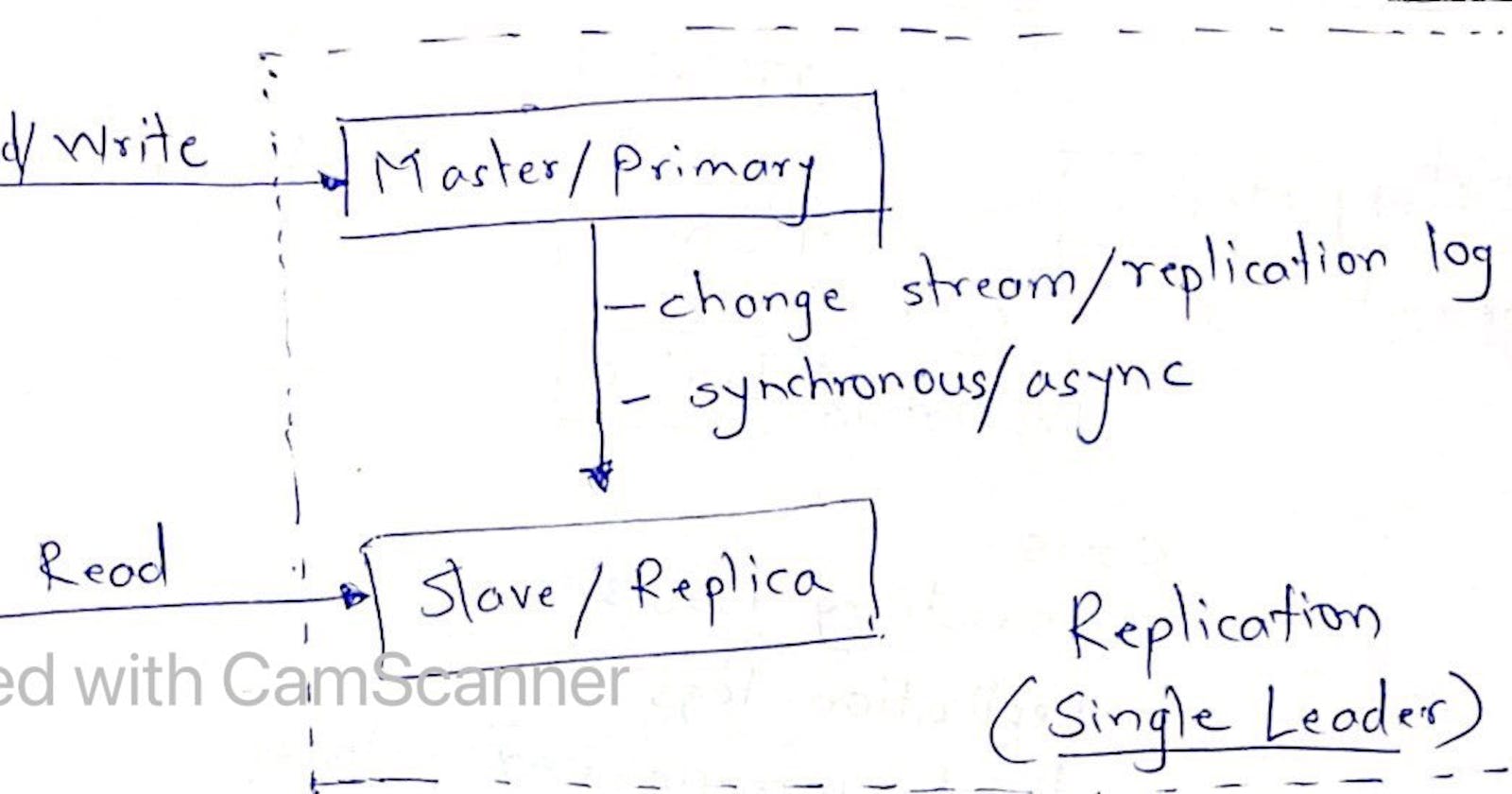
Single Leader Replication
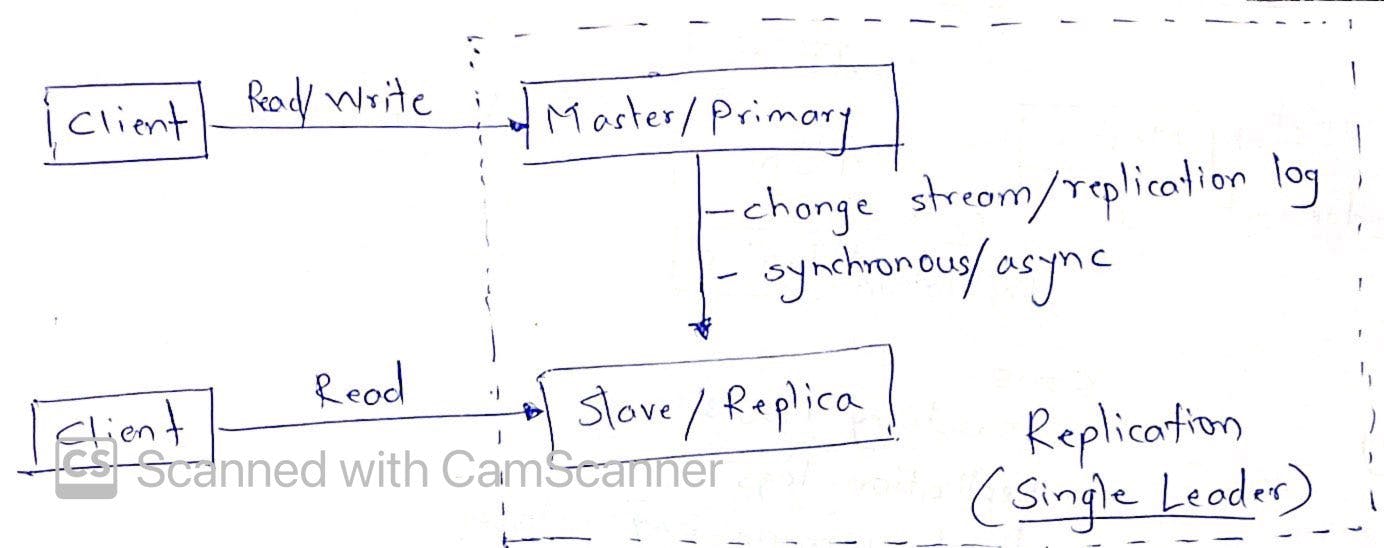 This is achieved via synchronous/asynchronous/semi-synchronous method as depicted in images below
This is achieved via synchronous/asynchronous/semi-synchronous method as depicted in images below
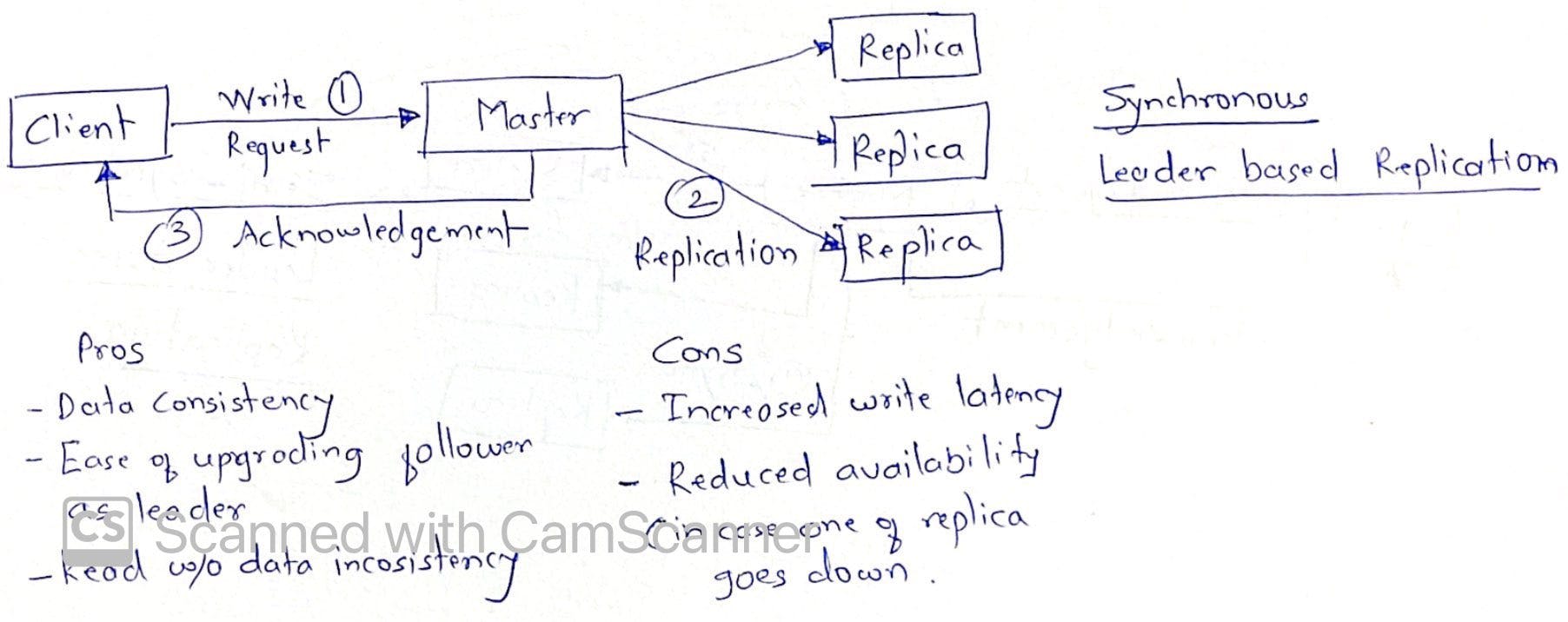
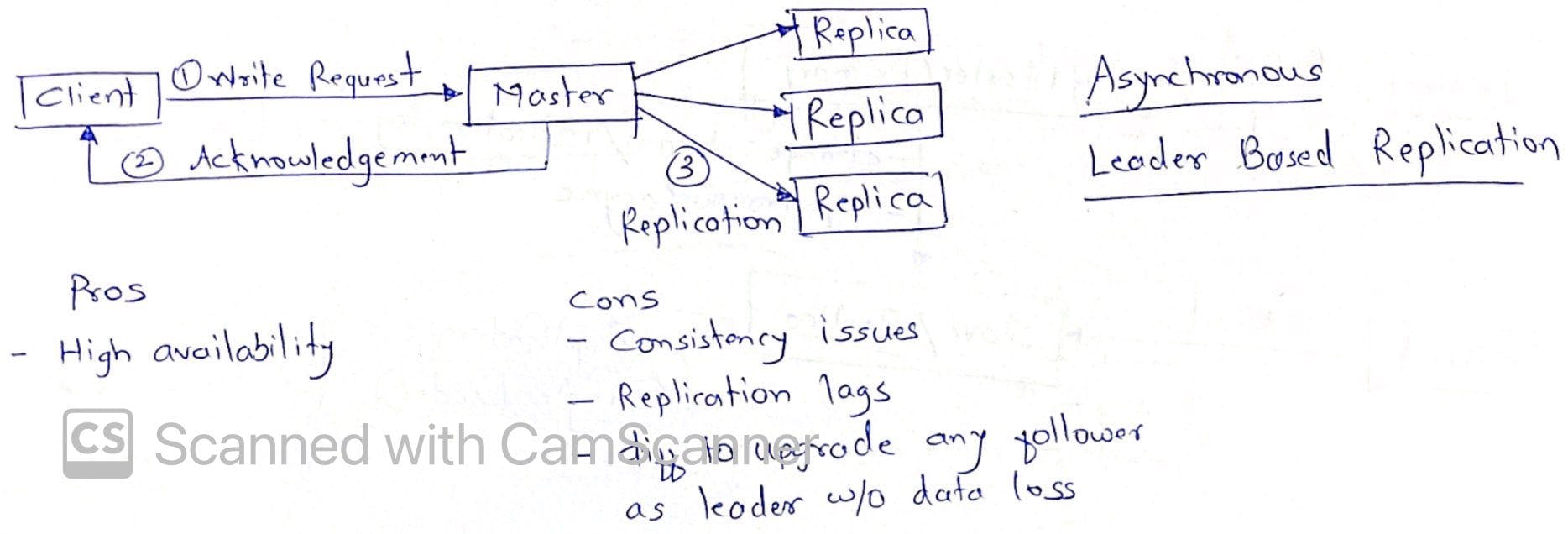
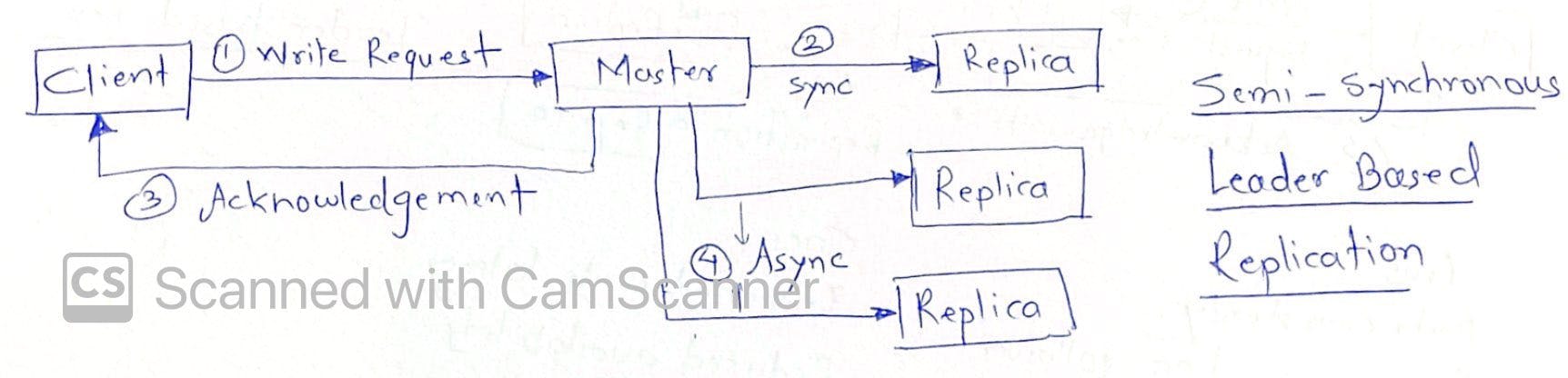
Ok, so how does system know if some node has died? If it is leader that dies, should I panic?
- Nodes talk with each others sending messages
- For any reason, if node doesn’t respond within defined timeout, its assumed dead
- Node can be processing with latency or even dead but once assumed dead, its dead
- If a dead node was a leader, a new leader is elected. If dead node comes back, it forcibly becomes follower to avoid split-brain issue
So how does a follower becomes leader, if leader dies?
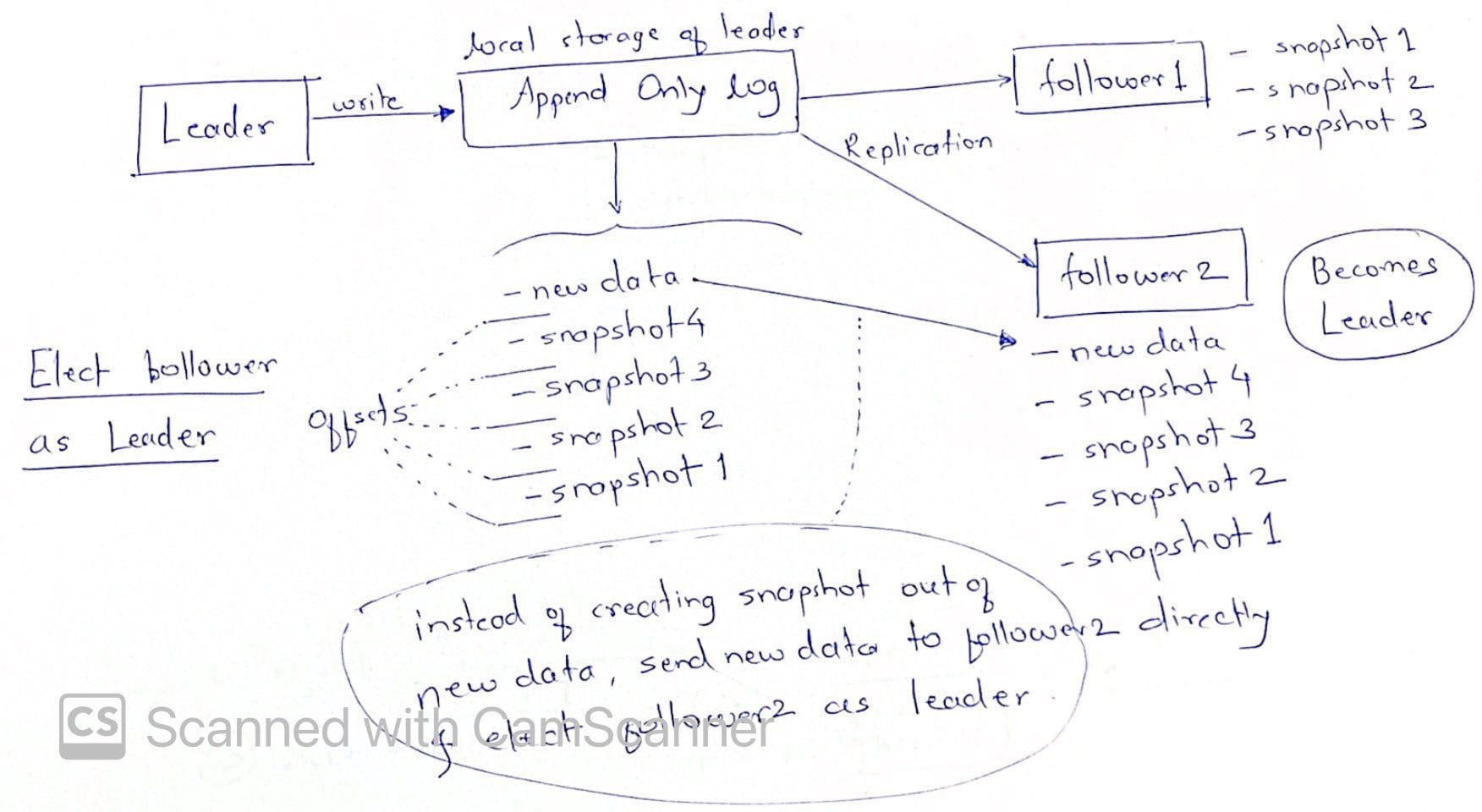
Continue to read on multileader and leaderless replication methods..