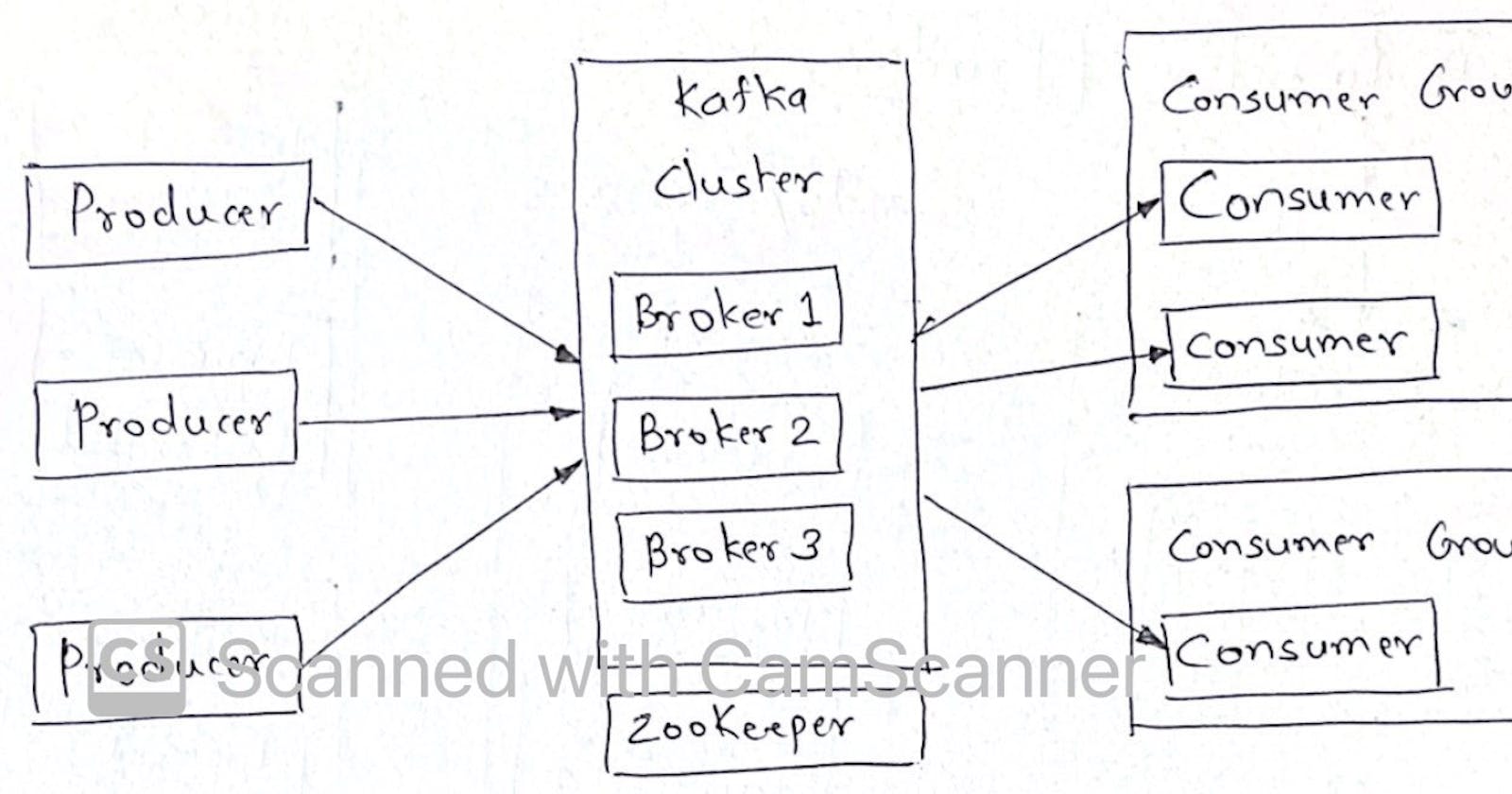


Kafka Architecture
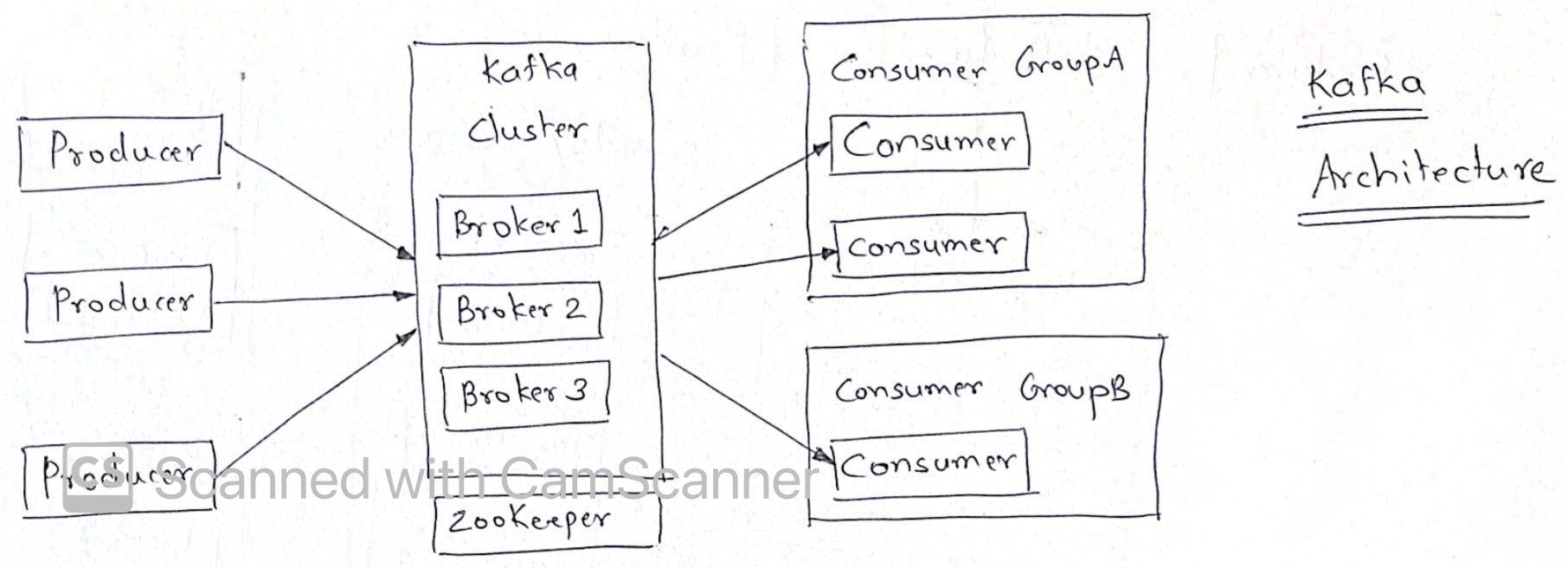
- Producers send messages (records) to kafka cluster which comprises of multiple brokers
- brokers manage the messages in terms of topics
- each topic has multiple partitions
- one or more consumers are grouped as consumer group, each consumer reads messages from different partitions of a topic to avoid reading duplicates
How does a topic look like?
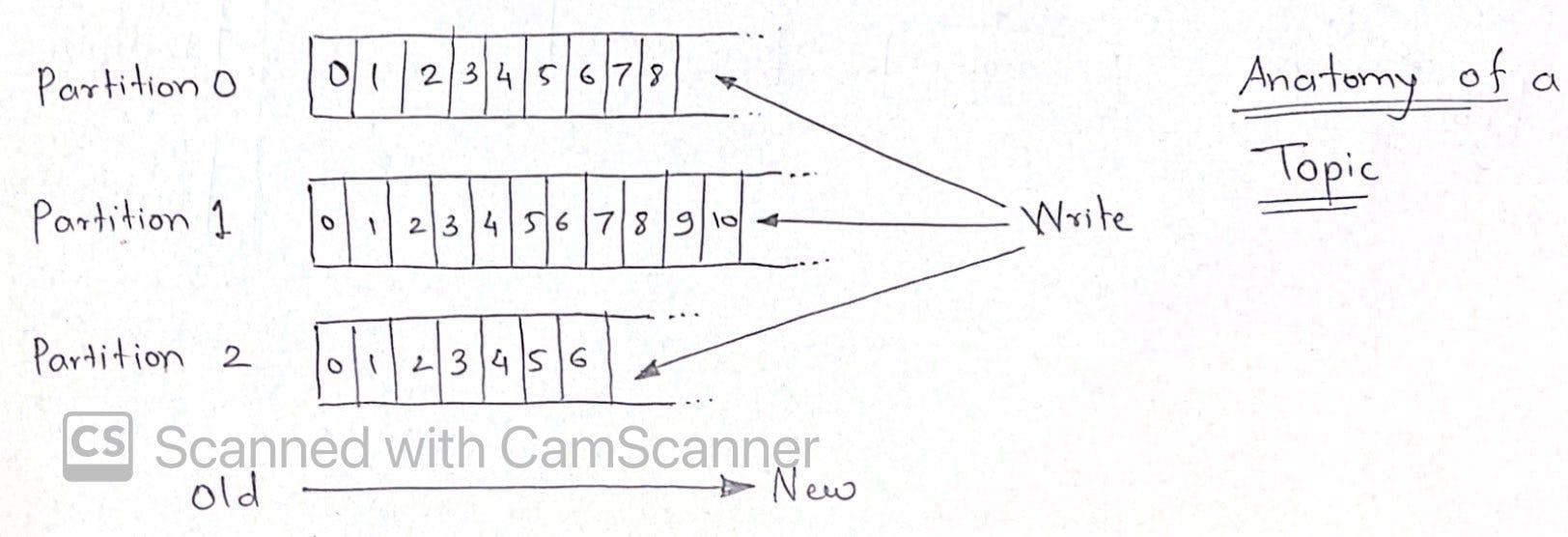
- Topic can have one or more partitions, number of partitions can't be changed once topic is created
- If messages being written do not have key, they are written in round robin fashion to all partitions. This doesn't guarantee message ordering hence defining a key is very important
- hash value is calculated from key of messages and data goes to corresponding partition example: username A-M going in partition1 vs N-Z going in partition2
- partitions are replicated on brokers based on replication factor.
- replication factor should be > 1 to ensure availability in case of broker failures. example: Replication factor=3 means create 3 replicas for each partition on different brokers
- replication factor = no of brokers is usually a good configuration
Data Flow and Replication
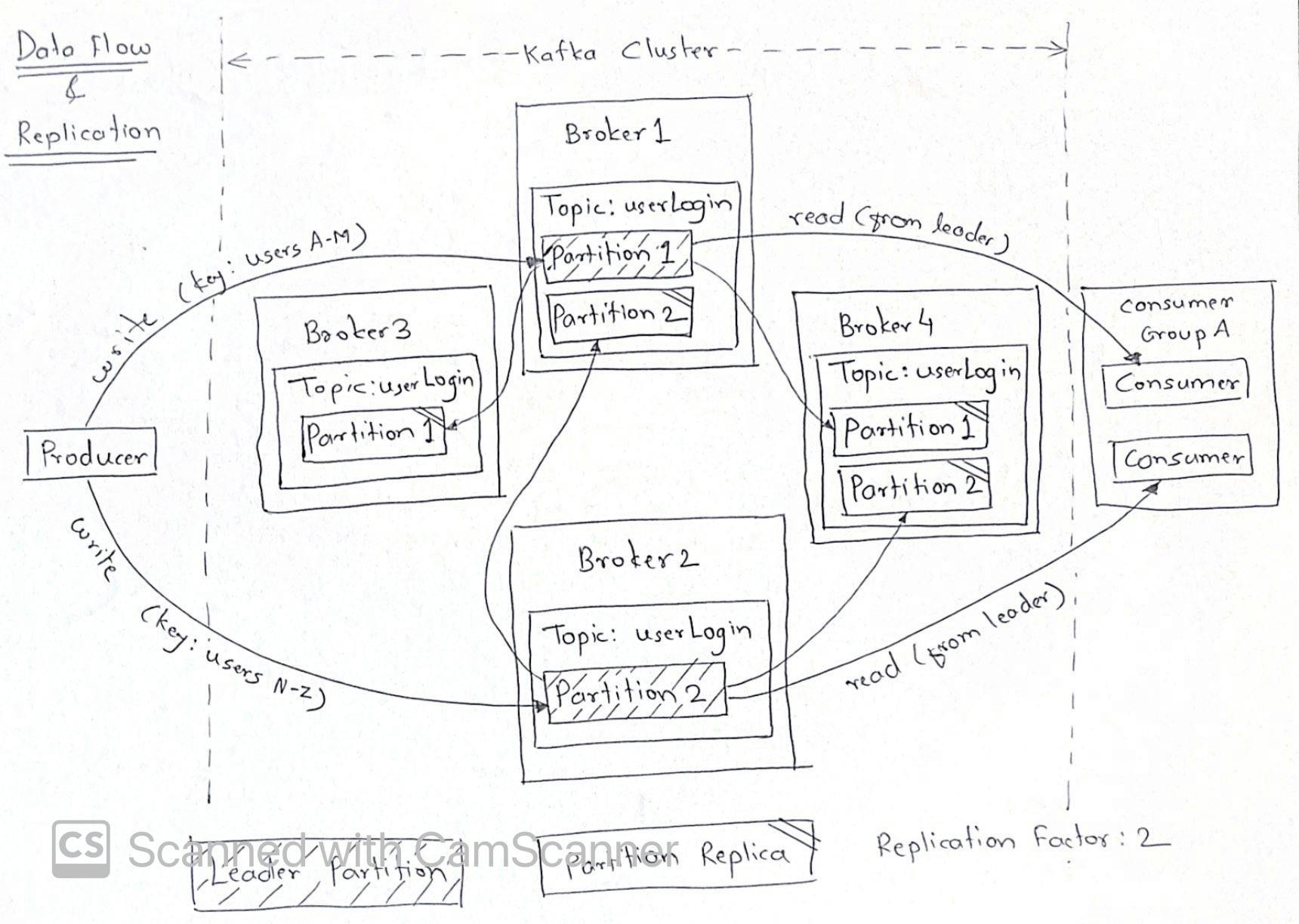
- producer writes messages to specific partitions, decided by kafka cluster by applying hashing to keys of messages
- this ensures reliability and ordering of messages in a partition
- there is only 1 leader partition of a topic on a broker at a time, other brokers might have replica of that leader partition based on replication factor
- every consumer in a consumer group reads messages from different leader partition to avoid duplicates
- in case broker with leader partition goes down, zookeeper selects replica partition on another broker as leader
Why is Kafka so fast?
Log-structured persistence (Sequential IO)
Kafka utilizes a segmented, append-only log, largely limiting itself to sequential I/O for both reads and writes. Data is accessed directly from disk, even so it is very fast due to sequential IO. Disk access is usually slower due to disk seek via random IO rather than actually accessing the location.
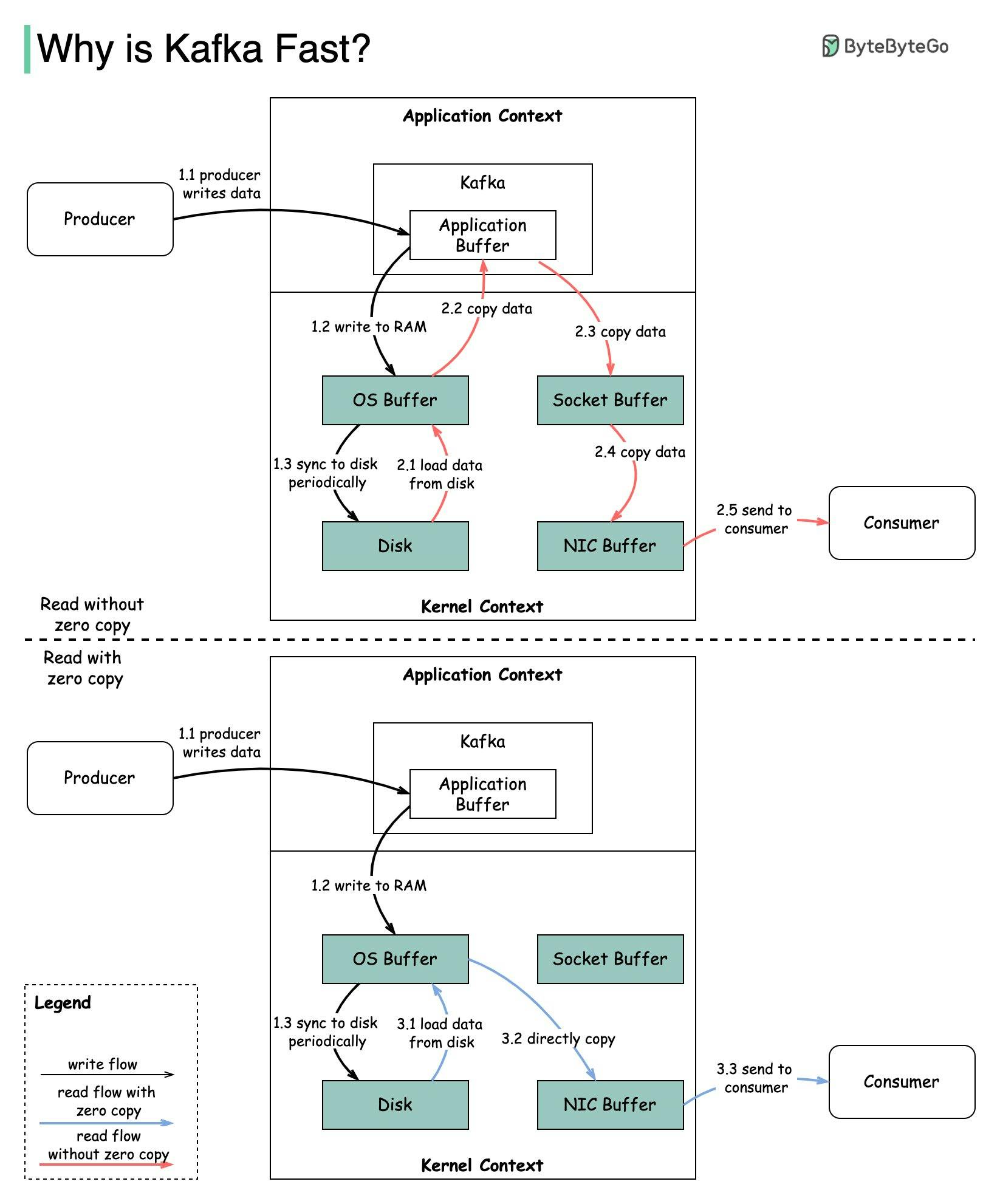
Zero copy
This illustration perfectly explains operations with and without zero copy
Record batching
Kafka clients and brokers will accumulate multiple records in a batch — for both reading and writing — before sending them over the network.
Batch compression
The impact of batching is particularly obvious when compression is enabled, as compression becomes generally more effective as the data size increases. It saves network bandwidth as well as broker's disk IO utilization
Cheap consumers
Unlike traditional MQ-style brokers which remove messages at point of consumption (incurring the penalty of random I/O), Kafka doesn’t remove messages after they are consumed — instead, it independently tracks offsets at each consumer group level. The progression of offsets themselves is published on an internal Kafka topic __consumer_offsets. Again, being an append-only operation, this is fast. Consumers in Kafka are ‘cheap’, insofar as they don’t mutate the log files (only the producer or internal Kafka processes are permitted to do that). This means that a large number of consumers may concurrently read from the same topic without overwhelming the cluster.
Unflushed buffered writes
Kafka doesn’t actually wait for acknowledging the write by flushing data from buffer to disk; the only requirement for an ACK is that the record has been written to the I/O buffer. This in fact is one of the primary reasons why kafka is fast. Downside of this is loss of unflushed data from buffer in case of node failure but replication comes to the rescue to recover the lost data.
Client side optimizations
Most databases and queues do all the heavy lifting while keeping the consumers/clients significantly simpler (e.g. connect to server using a think client using well known wire protocol) than servers. Kafka takes a different approach where all the heavy work is done on client side like, hashing the record keys to arrive at the correct partition index, checksumming the records and the compression of the record batch, etc. Client is aware about cluster metadata, so producers directly forward the writes to partition masters instead of asking broker to figure out that part. Consumer groups are aware about offsets and can make intelligent decisions themselves while sourcing records.
Detailed read reference: medium.com/swlh/why-kafka-is-so-fast-bde0d9..
Zookeeper
- it is distributed configuration and synchronization service
- serves as co-ordination interface between brokers and consumers
- stored basic metadata about cluster like topics, brokers, consumer offsets, leader election in case of leader failures, etc
- this replicates the data across its ensemble for easy recovery in case of broker/zookeeper failure
Note: ZooKeeper is external dependency in Kafka world and is being replaced by KRaft (which is metadata stored in distributed log internally)